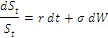fwd price ^ price of an existing eq-fwd position. Simple rule to remember —
QQ) not $0 — fwd price is well above $0. Usually close to the current price of the asset.
EE) nearly $0 — current “MTM value” (i.e. PnL) of an existing fwd contract is usually close to +-$0. In fact, at creation the contract has $0 value. This well-known statement assumes both parties negotiated the price based on arb pricing.
Q: With IBM fwd/futures contracts, is there something 2D like the IBM vol surface?
2 contexts, confusing to me (but not to everyone else since no one points them out) —
EE) After a fwd is sold, the contract has a delivery price “K” and also a fluctuating PnL/mark-to-market valuation “f” [1]. Like a stock position (how about a IRS?) the PnL can be positive/negative. At end of day 31/10/2015, the trading venue won’t report on the MTM prices of an “existing” contract (too many), but the 2 counter-parties would, for daily PnL report and VaR.
If I’m a large dealer, I may be long/short a lot of IBM forward contracts with various strikes and tenors — yes a 2D matrix…
[1] notation from P 109 [[hull]], also denoted F_t.
QQ) When a dealer quotes a price on an IBM forward contract for a given maturity, there’s a single price – the proposed delivery price. Trading venues publish these live quotes. Immediately after the proposed price is executed, the MTM value = $0, always
The “single” price quoted is in stark contrast to option market, where a dealer quotes on a 2D matrix of IBM options. Therefore the 2D matrix is more intrinsic (and well-documented) in option pricing than in fwd contract pricing.
—
In most contexts in my blog, “fwd price” refers to the QQ case. However, in PCP the fwd contract is the EE type, i.e. an existing fwd contract.
In the QQ context, the mid-quote is the fwd price.
Mathematically the QQ case fwd price is a function of spot price, interest rate and tenor. There’s a simple formula.
There’s also a simple formula defining the MTM valuation in EE context. Its formula is related to the QQ fwd quote formula.
Both pricing formulas derived from arbitrage/replication analysis.
—
EE is about existing fwd contracts. QQ is about current live quotes.
At valuation time (typically today), we can observe on the live market a ” fwd price”. Both prices evolve with time, and both follow underlier’s price S_t. Therefore, both prices are bivariate functions of (t,S). In fact, we can write down both functions —
QQ: F_t = S_t / Z_t ….. (“Logistics”) where Z_t is the discount factor i.e. the T-maturity discount bond’s price observed@ t
EE: p@f = S_t – K*Z_t
( Here I use p@f to mean price of a fwd contract. In literature, people use F to denote either of them!)
To get an intuitive feel for the formulas, we must become very familiar with fwd contract, since fwd price is defined based on it.
Fwd price is a number, like 102% of current underlier price. There exists only one fair fwd price. Even under other numeraires or other probability measures, we will never derive a different number.
In a quiz, Z0 or S0 may not be given to you, but in reality, these are the current, observed market prices. Even with these values unknown, F_t = S_t / Z_t formula still holds.
Black’s model – uses fwd price as underlie, or as a proxy of the real underlier (futures price)
Vanilla call’s hockey stick diagram has a fwd contract’s payoff curve as an asymptote. But this “fwd contract’s payoff curve” is not the same thing as current p@f, which is a single number.