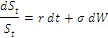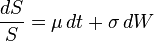See also — I have a long MSWord doc in my c:\0\b2b
Key — Start at discrete. Haksun’s example on coin flip…. Measure-P assigns 50/50 to head/tail. Measure-Q assigns 60/40 weights. Therefore we can see dQ/dP is a function (denoted M ), which maps each outcome (head/tail) to some amount of probability mass. Total probability mass adds up to 100%.
Requirement — the 2 measures are equivalent i.e. the pdf curve have exactly the same support. So M() is well-defined [1]. In the continuous case, suppose the original measure P is defined over a certain interval, then so is the function M(). However function M isn’t a distribution function like P, because it may not “add to 100%”. (I guess we just need the Q support to be a subset…)
Notation warning — V represents a particular event (like HT*TH), M(V) is a particular number, not a random variable IMO. Usually expectation is computed from probability. Here, however, probability is “defined” with expectation. I think when we view probability as a function, the input V is not a random variable like “X:=how many heads in 10 flips”, but a particular outcome like “X==2”.
Now we can look at the #1 important equation EQ1:
Q(V) := Ep [M(V) 1V] , where Ep () denotes expectation under the original Measure-P.
This equation defines a new probability distro “Q” using a P-expectation.
Now we can look at the #2 equation EQ2, mentioned in both Lawler’s notes and Haksun:
EQ[X] = Ep [ X M(X) ]
Notation warning — X is a random variable (such as how many heads in 10 flips), not a particular event like HT*TH. In this context, M(X) is a derived RV.
Key – here function M is used to “tilt” the original measure P. This tilting is supposed to be intuitive but not for me. The input to M() can be an event or (P141) a number! On P142 of Greg’s notes, M itself is a random variable.
Next look at a continuous distro.
Key – to develop intuition, use binomial approximation, the basis of computer simulation.
Key – in continuous setting, the “outcomes” are entire paths. Think of 1000 paths simulated. Each path gets a probability mass under P and under Q. Some paths get higher prob under Q than under P; the other paths get lower prob under Q.
The magic – with a certain tilting function, a BM with a constant drift rate C will “transform” to a symmetric BM. That magic tilting function happens to be …
I wonder what this magic tilting function looks like as a graph. Greg said it’s the exponential shape as given at end of P146, assuming m is a positive constant like 1.
In simple cases like this, the driftless BM would acquire a Positive drift via a Positive tilt. Intuitively, it’s just _weighted_average_:
* For the coin, physical measure says 50/50, but the new measure *assigns* more weight to head, so weighted average would be tilted up, positively towards heads.
* For the SBM, physical measure says 50/50, but the new measure *assigns” more weight to positive paths, so the new expectation is no longer 0 but positive.
[1] This function M is also described as a RV with Ep [M] = 1. For some outcomes Q assigns higher probability mass than P, and lower for other outcomes. Average out to be equal.